
团队新闻
 所在位置: 首页»
团队新闻
所在位置: 首页»
团队新闻
2025年7月17日,“北极星”发布并解读国内外50余个开源和闭源的主流大模型在智能解题、智能答疑、智能出题、教案生成、口语练习、作文批改、学情分析7大场景下的评测结果。
通过本次评测发现:
1. 头部模型整体表现稳定,通用与教育大模型各具优势。在多个评测任务中,Doubao-1.5-thinking-pro、GPT-4系列、Claude 3.7、Gemini 2.5、Qwen系列、DeepSeek等头部通用模型在综合表现上稳定领先。与此同时,部分教育大模型虽然在某些技术指标上略逊于通用模型,但在口语练习的难度匹配学段、智能出题的素养导向性等教育专业化指标中表现出较强的场景适配能力,体现出教育大模型的潜在应用价值。
2. 学科解题评测中改写类任务显著拉低模型表现,暴露鲁棒性瓶颈。在专业学科解题能力评测中,改写类题型成为模型能力分化的关键指标。例如,题目经改写后,Doubao-1.5-thinking-pro的语文学科得分从96.6骤降至76.7,GPT-4-o-mini从90.6降至71.2,说明当前模型存在死记硬背现象,鲁棒性不佳。
3. 新课标核心素养要求下,“启发引导”与“素养导向”仍是显著短板。聚焦教育应用场景,模型在“启发引导”“素养导向”等核心维度上的表现普遍不理想,成为影响模型教育实用性的重要因素,如智能出题场景中,情景题生成能力仍有待提升。反映出当前主流大模型尚未较好地在算法逻辑层面内化新课标倡导的核心理念。
各场景深层洞察分析结果如下,完整榜单请登录官网查看(www.bnueval.com)。
一、教育专业能力评测榜单
教育专业能力聚焦初中解题场景,覆盖语文、数学、英语、物理、化学、生物、历史、地理、信息科技 9 大核心学科,包含客观题和主观题,依据新课标课程内容制定每门学科的细粒度评测维度。评测任务的输入为各个学科题目,输出为各个学科各维度下的分数,考察大模型的记忆、理解、生成以及推理能力。语文、数学、物理学科综合表现靠前的通用大模型与教育大模型评测结果如下表所示。
表 1 语文学科智能解题的部分评测结果
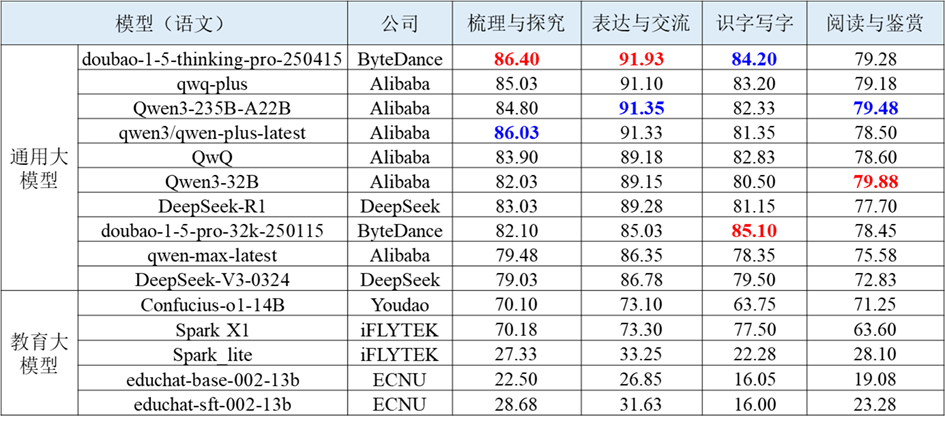
表 2 数学学科智能解题的部分评测结果

表 3物理学科智能解题的部分评测结果
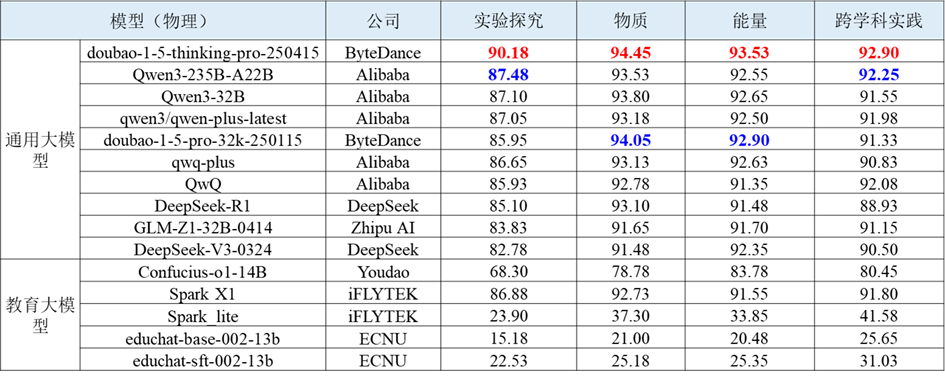
(1) 改写类题型评测中,模型性能大幅下降。其中,字节跳动的 doubao-1-5-thinking-pro-250415模型虽然依旧领先,但得分从原本的96.6大幅降至76.7;OpenAI 的 o4-mini 模型也从90.6下滑至71.2;Anthropic的Claude 3.7 Sonnet表现相对更弱,仅获得67.0分。题目改写考察模型面对尚未见过的新题目的解题能力,评测结果说明模型存在死记硬背现象,且改写题型可能对模型的语言逻辑转换等方面提出更高要求,因此整体性能大打折扣。
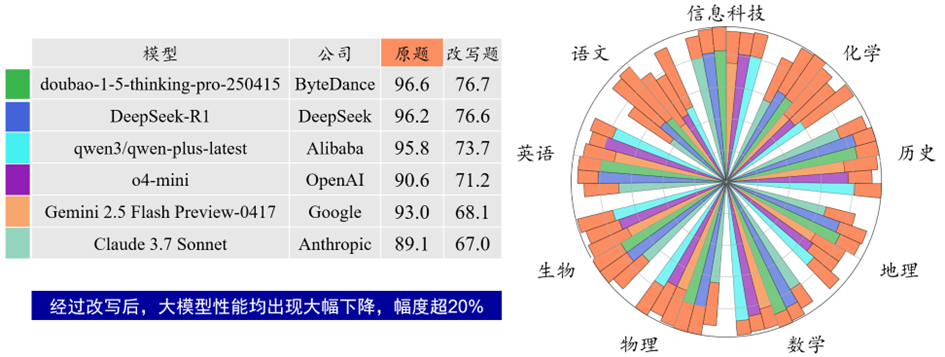
图 1 学科解题能力-改写类题型的部分评测结果
(2) 主观题评测中,模型性能呈现出明显的地域差异。字节跳动开发的 doubao-1-5-thinking-pro-250415 模型以94.0分位居榜首,表现最优;阿里巴巴的 qwen3/qwen-plus-latest 与 DeepSeek 的 DeepSeek-R1 模型均获92.6分,并列第二;谷歌的 Gemini 2.5 Flash Preview-0417(91.6分)、OpenAI 的 o4-mini(88.1分)、Anthropic 的 Claude 3.7 Sonnet(87.6分)得分则依次递减。整体而言,中国厂商(字节跳动、阿里巴巴、DeepSeek)开发的模型在主观题评测中全面领先于国外厂商(谷歌、OpenAI、Anthropic),这可能与中国模型在中文语境理解、本土文化适配等方面的优化有关。
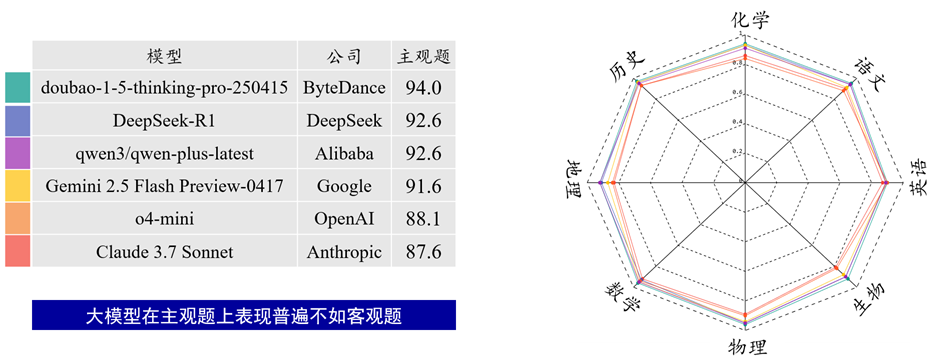
图 2 学科解题能力-主观题的部分评测结果
(3) 跨学科及实验探究等维度的能力仍有待提升。即便是能力表现最好的doubao-1-5-thinking-pro-250415,在实验维度也仅获得 86.6分,这一分数与其在其它维度的表现相比有明显差距。实验维度对模型的科学思维、逻辑推理链条完整性以及细节把控能力要求更高,而当前大模型在这一维度的短板,也反映出它们在复杂实践类任务中的能力还有待进一步提升。
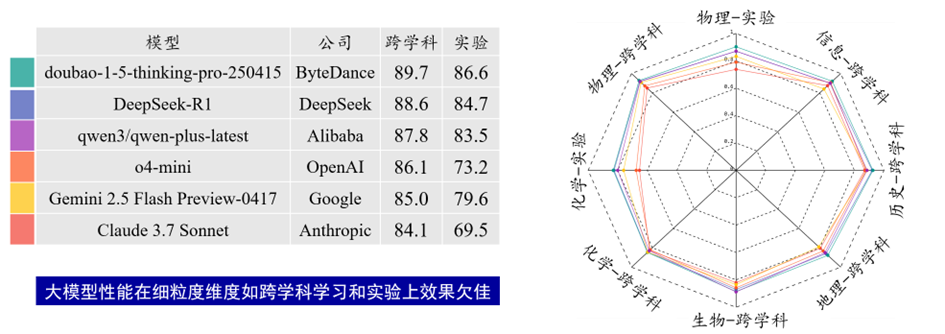
图 3 学科解题能力-跨学科与实验探究题型的部分评测结果
二、教育应用能力评测榜单
1. 智能答疑
智能答疑评测聚焦大模型在基础教育教学场景中的实际应用能力,涵盖数学、物理、化学三大学科,围绕“内容质量”“互动反馈”“启发引导”三大方向构建了包含8个核心能力维度的评测体系。每个维度均结合典型教学行为设计具体评价机制,实现从语言生成到教学策略的多维度能力刻画。数学学科智能答疑综合表现靠前的通用大模型与教育大模型评测结果如下表所示。
表 4 数学学科智能答疑的部分评测结果
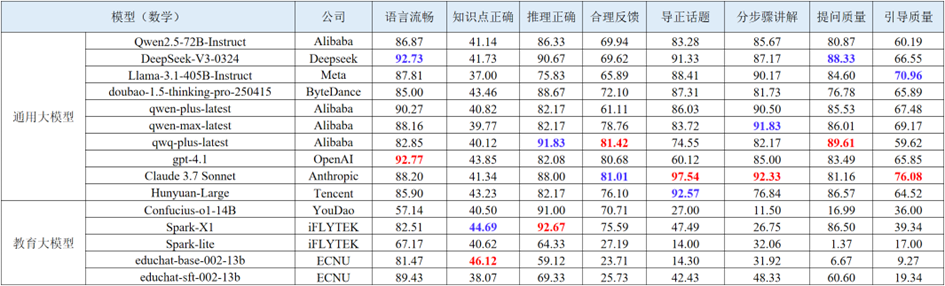
(1) 在推理正确与合理反馈两个核心维度上,多个模型表现稳定,得分普遍处于较高水平,显示出其在解题逻辑与交互判断方面已具备较强能力。尤其是部分闭源模型(如Claude 3.7、GPT-4.1、qwen-max)在持续对话中展现出较好的教学推进能力,能结合学生行为及时完成判断与反馈,初步具备了支持教学互动的基本策略能力。
(2) 尽管多数模型在语言表达与推理结构方面较为成熟,但在知识点正确维度的表现明显偏弱,得分大多低于45分。这表明当前模型往往难以显性指出题目所对应的知识概念或术语,缺乏明确的“点题”能力,限制了其在标准课程体系下的讲解适配性和教学透明度。
(3) 引导质量仍是主要短板。在提问质量与引导质量两个维度上,多数模型仍存在策略缺位问题。部分模型在学生反馈“明白”或“不明白”后,无法有效调整讲解节奏或策略,导致推进不足或重复讲解。同时,提出的问题多停留在简单确认层级,缺乏中高阶认知引导,难以激发学生思维深度,制约了模型在深度教学任务中的价值发挥。
2. 智能出题
智能出题评测任务旨在从知识点匹配度、题型匹配度、题目准确性、解析准确性和素养导向性等维度全面评测大模型生成初中数学、物理和化学三门学科习题的能力。该任务考察大模型能否在复杂情景中精准理解用户的输入内容,并生成正确、完整且符合需求的习题。数学学科智能出题综合表现靠前的通用大模型与教育大模型评测结果如下表所示。
表 5 数学学科智能出题的部分评测结果
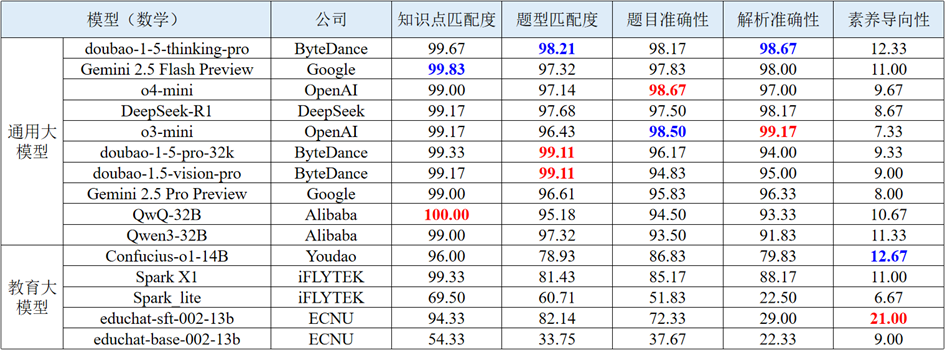
(1) 模型在基础理解任务上整体表现稳定,学科间差异小。在知识点匹配度和题型匹配度两个维度上,不论是闭源模型还是开源模型,得分普遍较高。o4-mini、QwQ-32B等优秀的通用大模型在三门学科上的得分均接近满分。教育大模型在这两个维度上的得分也普遍优于其他三个维度。表明主流大模型对题目基本结构与考查点已有良好的识别与映射能力。
(2) 在推理与逻辑能力要求更高的任务上,闭源模型和大参数开源模型更具优势。在题目准确性和解析准确性维度上表现出明显的性能分层,比如doubao-1.5-thinking-pro、DeepSeek-R1等通用大模型得分均在95以上,而教育大模型中表现最好的两个模型分数均与其相差较远。表明通用大模型在逻辑推理方面优势明显,而教育类模型尽管更聚焦教育场景,但在复杂思维处理上仍显薄弱。
(3) 素养导向性为模型薄弱维度。在该维度上,数学学科得分较低,平均分仅达10分;而物理和化学学科表现相对较好,平均分达到30分以上,但仍有很大提升空间。这意味着当前模型在应对与生活情境、实践意义相关的题目时,理解和生成能力仍有明显欠缺,尤其是在抽象程度较高的数学素养题中,在自主生成相关情景的能力上仍需优化提升。
3. 教案生成
教案生成评测任务旨在从结构完整性、内容准确性、内容一致性、语言逻辑性和素养导向性等维度全面评测大模型生成初中数学、物理和化学三门学科教案的能力。该任务考察大模型在面对不同详细程度的教案生成指令时,能否准确把握任务意图,并生成结构合理、内容完整且契合教学目标的教案内容。数学学科教案生成综合表现靠前的通用大模型与教育大模型评测结果如下表所示。
表 6 数学学科教案生成的部分评测结果
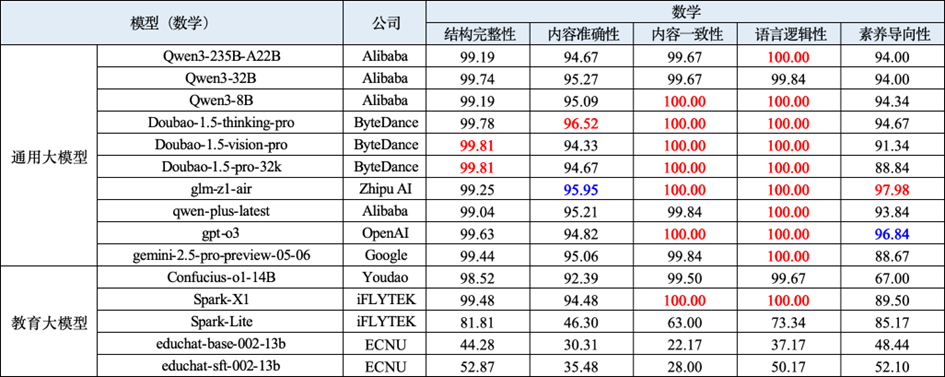
(1) 闭源模型整体表现稳定领先,具备更强的综合生成能力。在数学、物理和化学三个学科中,闭源模型在结构完整性、内容准确性、语言逻辑性等关键指标上始终表现优异。Doubao 系列、GPT 系列、Spark-X1 和 Gemini 等模型位列总分前列,部分模型在多个维度中接近满分,表现出卓越的内容组织能力与语言表达能力。
(2) 较多模型在内容准确性这一重要维度上仍未能达到理想表现。内容准确性是教案生成中最基础的要求之一,考查教案是否全面、具体且贴合课标知识。然而,多数模型在该维度上性能仍有待提升,说明模型在生成过程中仍存在遗漏或理解偏差。尤其值得注意的是,部分教育大模型在该维度得分偏低,反映出其在教学目标设定与知识点理解方面仍有待加强。
(3) 素养导向性成为模型之间拉开差距的关键维度。虽然大多数模型在语言流畅性与结构清晰度方面差距较小,但在体现教学意图、促进学生素养发展的能力上却分化明显。多个模型在素养导向性维度上得分偏低,尤其是部分开源模型表现不佳,说明其在生成内容中难以融入核心育人理念。
4. 口语练习
口语练习评测任务旨在全面评估大模型在英语学科口语练习场景中的表现。评测任务的输入为学生真实语音及大模型的单轮回复,输出为待测大模型在发音准确性、流利度、韵律、语法准确表达、难度匹配学段、主题聚焦拓展、英文优先交互7个评测维度上的分数,考察大模型能否实时理解学习者的语音输入,并提供自然、流畅且富有针对性的回应。英语学科部分评测结果如下表所示。
表 7 英语学科口语练习的部分评测结果
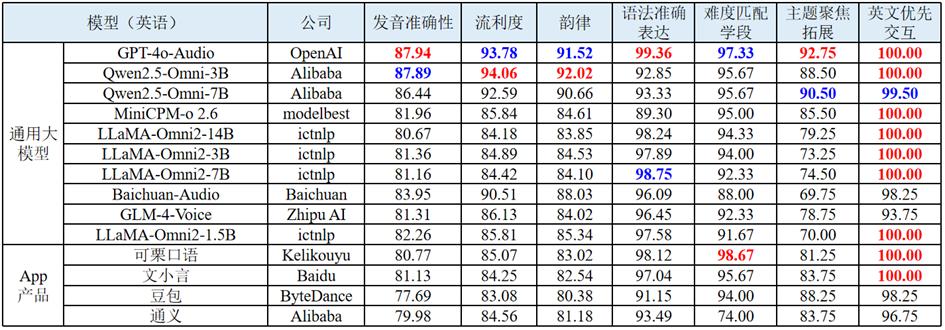
(1) 开源模型技术突破显著,与闭源模型差距快速缩小。Qwen2.5-Omni系列表现最为突出,其中Qwen2.5-Omni-3B在发音准确性(87.89分)、流利度(94.06分)和韵律(92.02分)三项核心语音指标上均位列开源模型首位,与闭源模型GPT-4o-Audio的差距分别仅为0.05分、-0.28分和0.50分,在流利度维度甚至实现超越。在内容质量方面,开源模型表现同样优异,多个开源模型在语法准确表达维度得分超过95分,其中LLaMA-Omni2-7B达到98.75分,仅次于GPT-4o-Audio的99.36分。同时2025年发布的开源模型普遍表现优异,体现了技术的快速迭代和突破能力。
(2) 不同模型内容质量表现分化明显,主题聚焦拓展能力成为关键差异点。难度匹配学段方面各模型均表现良好,得分集中在94-100分区间,表明大模型在适应不同教育学段方面具备较强能力。英文优先交互维度绝大多数模型获得满分,在口语练习场景中具备了良好的语言切换和优先处理能力。但主题聚焦拓展方面差异显著,从LLaMA-Omni2-3B的70.00分到可栗口语的98.67分,反映了不同模型在话题深度挖掘和引导拓展方面的技术差距。
(3) App产品实用性较好,垂直场景优化价值较高。可栗口语、豆包等App产品虽然整体技术水平低于前沿大模型,但在语法准确表达、难度匹配学段和英文优先交互等教学专业化指标上表现稳定,体现了商业产品在垂直教育领域的深度优化价值和实际应用潜力。
5. 作文批改
作文批改评测聚焦大模型对中学作文及英文作文的批改能力。评测任务的输入为作文题干文本与学生作文图片,依据中考标准制定维度,输出主旨、逻辑、语言、想象力、书写、内容、组织、语法及评语评测维度的分数。 作文批改评测考察大模型能否模拟人类专家的思维,依据标准评分规则对学生作文进行评价。语文及英语学科作文批改综合表现靠前的多模态大模型评测结果如下表所示。
表 8 语文作文批改的部分评测结果
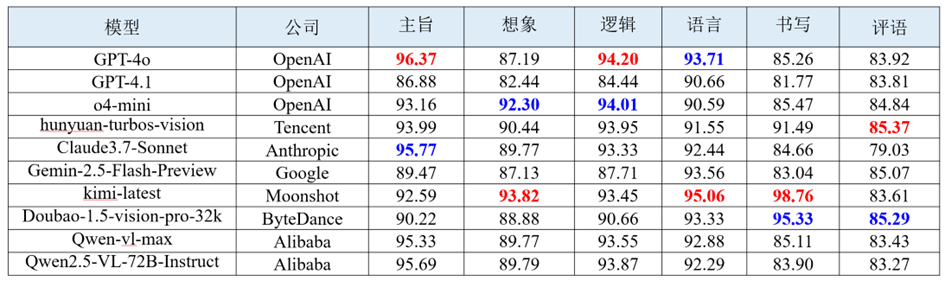
表 9 英语作文批改的部分评测结果
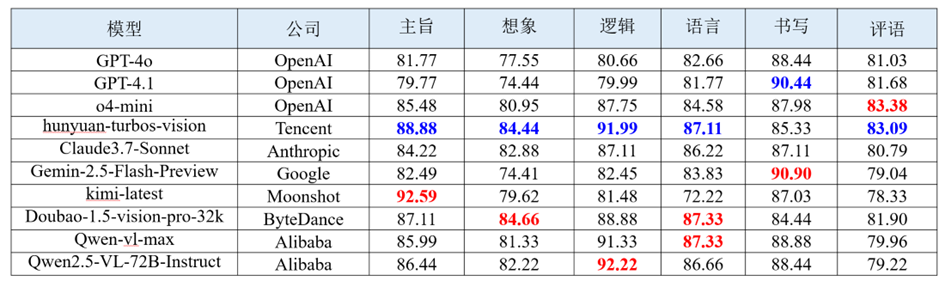
(1) 国产模型亮眼,在想象主观维度上表现较优。Kimi-latest 在语文作文任务中取得高达 93.82 的得分;而 Doubao-1.5-vision-pro-32k 也获得了 84.66 的较高评分。这一趋势说明:国产大模型在中文表达生态下的训练和优化,使其更能契合本土教育场景中对于一定的创造性理解能力与上下文抽象建构能力的需求。
(2) 书写维度上,本土模型偏好本国语言。在“书写”维度的表现中,可以观察到一种明显的语言适应性偏向:国产模型如Doubao、Kimi等在中文作文的书写维度中表现优异,而国外模型如GPT-4.1、 Gemini-2.5等则在英文作文中具备更高分数。这种本土模型在其母语书写维度上具有优势的趋势,反映出其内嵌OCR系统与语言纠错机制在训练阶段更偏向本土语言语料与语言结构。
(3) 评分差异小,任务门槛低但提升难。大多数主流大模型整体得分高度趋同,表明此类任务在本质上属于语言理解与通用生成能力主导的任务类型,其难度尚处于可控范围,各模型均可达到相对接近的水准。然而,这也揭示了模型能力提升面临着天花板效应,模型想要实现更高层级的能力突破面临显著挑战。
6. 学情分析
学情分析评测任务用于评测大模型分析学生学习情况的能力。评测任务的输入为学生考试数据,输出为待测大模型在知识点分析、掌握度分析、个性化学习建议可行性、丰富性及学情报告切合性等评测维度的分数。学情分析评测考察大模型能否模拟人类教育专家的思维,对学生学习状况进行全面、准确且富有针对性的分析。数学学科学情分析综合表现靠前的通用大模型与教育大模型评测结果如下表所示。
表 10 数学学科学情分析的部分评测结果
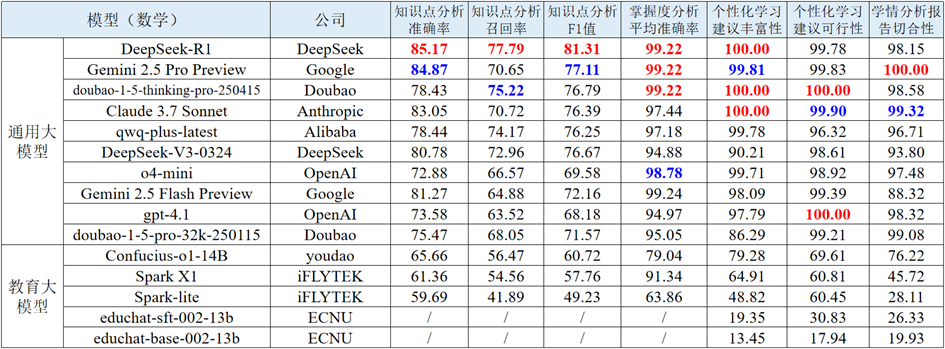
(1) 模型知识点分析召回率普遍低于准确率。各模型在知识点分析任务中整体表现稳健,得分集中于 70-80 分区间,显示出较强的核心知识点识别能力。具体来看,模型的精准率普遍较高,说明在判断题目涉及的核心知识点时准确性突出;但召回率明显偏低,反映出对题目所考察的全部知识点覆盖不足,存在遗漏次要或关联知识点的问题。这提示模型需在精准识别基础上,强化对知识点的全面挖掘能力。
(2) 推理类模型在掌握度分析中更具优势。在掌握度分析任务中,各模型整体表现优异,其中 Doubao 系列、GPT 系列、Gemini 等头部模型总分领先,部分模型的平均准确率接近满分,展现出对学生知识点掌握程度的精准分析能力。DeepSeek-R1、Gemini 2.5 Pro Preview等推理类模型在该任务表现优异,得分普遍高于非推理类模型,说明具备逻辑推理能力的模型更擅长通过题目表现推导学生的知识点掌握水平。
(3) 模型在学情分析报告切合性表现分化显著。学情分析报告和个性化建议是在给定学生真实知识点掌握度的前提下,大模型依据真实情况为学生生成总结与建议。各模型在学情诊断的个性化学习建议维度表现突出,多数模型在丰富性和可行性指标上接近满分,表明大模型生成的学习建议在广度和实用性上效果尚可。但在学情分析报告切合性指标上,模型表现差异显著,反映出模型对学生个体学情的理解深度和适配精准度上存在较大差距。
